


DeepMind built an AI that invents better AI
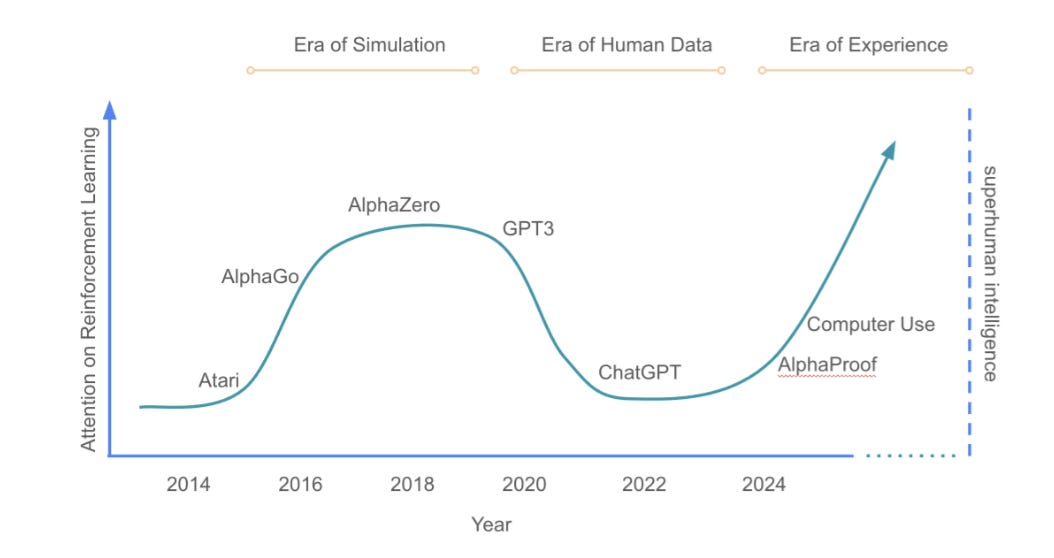
We are entering the Era of AI Experience

“We stand on the threshold of a new era in artificial intelligence that promises to achieve an unprecedented level of ability. A new generation of agents will acquire superhuman capabilities by learning predominantly from experience.”
~ David Silver and Richard Sutton,
A pivotal moment in the evolution of AI
Despite being written by two of the world's leading AI developers actively engaged in new efforts, it's rare for a research paper like the one below not to make headlines.
First, in a short interview David Silver confirms that they have built a system that used Reinforcement Learning (RL) to discover its own RL algorithms. This AI-designed system outperformed all human-created RL algorithms developed over the years. Essentially, Google DeepMind built an AI that invents better AI.
Second, the paper seeks to take AI back to its roots, to the early compulsions of curiosity: trial, error, feedback. David Silver and Richard Sutton, two AI researchers with more epistemological steel than most, have composed a missive that reads less like a proclamation and more like a reorientation, a resetting of AI’s moral compass toward what might actually build superintelligence. They call it “The Era of Experience”, and state
RL “will unlock in many domains new capabilities that surpass those possessed by any human.”
To grasp the weight of their argument, let us retrace the footprints leading here. The current AI systems rely heavily on human data: vast digital repositories of Reddit tirades, Shakespearean prose, dermatology textbooks, and leaked chess games. Machines, like eager apprentices, learned to mimic our thinking, our errors, even our hubris. They became fluent in language but dumb to consequence, expert in form but ignorant of effect. These systems could conjure haikus about black holes or summarize Wittgenstein, but ask them to build a better battery or reform a broken healthcare system, and the performance was sterile, not science. Although, OpenAI recently announced that their systems are now helping with new discoveries.
Silver and Sutton write,
“While imitating humans is enough to reproduce many human capabilities to a competent level, this approach in isolation has not and likely cannot achieve superhuman intelligence.” They add: “The pace of progress driven solely by supervised learning from human data is demonstrably slowing, signalling the need for a new approach.”
Quietly damning sentences. What they are saying, without slamming the gavel, as my dear friend the judge is wont to do, is that the ceiling of mimicry has been reached. We are now banging our heads against the current method.
Enter the second act: experience. This is not some romantic notion of machine spiritual awakening. It is colder, more beautiful from a development perspective. It is the agent as learner, not from curated samples or censored history, but from the raw, unfiltered theater of the world. Trial becomes tutor. Feedback becomes gospel. AlphaProof, the case study they cite with almost clinical detachment, was first trained on a mere hundred thousand formal mathematical proofs. Then, it broke free. Using reinforcement learning, it generated a hundred million more, uncovering proofs not in books, but in the crevices of formal logic. It didn’t imitate mathematicians. It became one with the science.
Let this sink in. This shift marks a break from learned mimicry, AlphaProof did not generalize from textbooks or lectures. It interacted with formal logic directly, iterating through symbolic landscapes inaccessible to any human teacher. Its development trajectory is not lonely in a sentimental sense, but isolated by method: it learns not from us, but from the structure of problems themselves.
Note - AlphaProof recently became the first program to achieve a medal in the International Mathematical Olympiad.
The authors reiterate the success of DeepSeek stating it (DeepSeek):
“underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies.”
Designing an Intelligence
But this shift isn't just about scale or technical elegance. It’s about divorce. A divorce from the reassuring imitation of human cognition. AI will not be our reflection in this new era; it will be something alien. Something that learns from the world not as we see it, but as it reacts to them.
And so the authors introduce four central tenets of the coming age: streams, actions and observations, grounded rewards, and experiential reasoning. These are not abstractions. They’re architectural pillars.
Streams, first, undo the episodic structure of current AI interactions. No longer will an agent live in the goldfish bowl of prompt and response. Like a human life, its understanding will be sequential, historical. This enables long-term strategies, a health agent that remembers your January insomnia in July, or a language tutor that recognizes your mispronunciation patterns after a few attempts and stores it in its memory. Streams directly reintroduce and demand temporal abstraction, one of the classic pillars of reinforcement learning (RL), as first formalized by Sutton in his foundational work on options. The authors write:
“…the agent takes a sequence of steps so as to maximise long-term success with respect to the specified goal. An individual step may not provide any immediate benefit, or may even be detrimental in the short term, but may nevertheless contribute in aggregate to longer term success. This contrasts strongly with current AI systems that provide immediate responses to requests, without any ability to measure or optimise the future consequences of their actions on the environment.”
Actions and observations wrest agency away from text tokens. Current AI interacts via keyboards and server calls. Tomorrow's AI will have eyes and hands, albeit digital ones, it will touch, taste, push, and pull the world. This is what animals do. This is what children do. And it is how we learn. These interactions support the construction of dynamic world models, a foundational element Sutton pioneered through the Dyna architecture, allowing agents to predict, adapt, and plan.
Grounded rewards dismantle the priesthood of human preference. The reward becomes not what a human deems good, but what empirically improves outcomes. A cake is not good because a Michelin judge says so; it is good if someone eats it, smiles, and doesn’t get food poisoning. AI will learn by that. But the paper wisely does not suggest abandoning human input, it proposes a subtle recalibration: humans help shape the function that selects which grounded signals matter. It becomes a bi-level optimization process: users specify broad goals; agents learn from reality. And here too we return to Sutton, whose early work on reward prediction via temporal difference learning laid the groundwork for all such adaptive formulations.
And then comes the fourth pillar: experiential reasoning. This may be the most heretical of all. Here, the authors suggest something almost subversive: that human thought is not the pinnacle of cognition. The era of human data worshipped the chain-of-thought prompt. But, as they put it,
“…it is highly unlikely that human language provides the optimal instance of a universal computer.”
A high bar of trust and responsibility
Machines may soon develop alien logics that resemble neither syllogism nor dialectic. They may reason not like Socrates, but like evolution, blind, brutal, and breathtakingly effective. Here again, the RL roots are apparent: planning through value estimation, simulating outcomes via world models, and optimizing for future returns. This is thinking, but not as we know it.
All this leads to a provocative thesis: that learning from experience, real-world, physical, iterative engagement, is not merely a technique, but a philosophy. It echoes Dewey more than Descartes. Not “I think, therefore I am” but I act, observe, and update, therefore I become.
Yet the paper is not utopian. Silver and Sutton acknowledge the lurking shadows. Agents that operate independently over time may drift, or worse, act with consequences untraceable to human intent. If misaligned, such agents don’t just err, they persist in erring. They optimize in wrong directions. They become efficient at harm.
But here too, experience offers hope. An agent grounded in reality will notice when the world grimaces. When the human frowns. When the temperature rises or the heart rate falls. Feedback loops, slow and imperfect as they are, allow course correction. Unlike rigidly programmed systems, experiential agents can change. That may be their salvation, and ours. Moreover, because grounded signals often emerge from the physical or social environment, think sleep metrics, climate data, or user-reported satisfaction, these systems have an inherent connection to consequence, rather than a dependence on assumption.
Discover creative new behaviors
There is something poetic, and unnerving, in how this paper closes the loop. Decades ago, Sutton, the co-author, wrote the canonical text on reinforcement learning. It was about value functions and Bellman equations, but also about a dream: that agents could learn on their own. That dream was somewhat hijacked by the seductive ease of pretraining and prompt engineering. But the wheel has turned again. The baby, once abandoned with the bathwater, is crawling back.
David Silver is the pioneer developer behind AlphaGo and many of the major Google AI breakthroughs. Just to reiterate one of Silver and Sutton’s big points:
“The era of experience,” they write, “will unlock in many domains new capabilities that surpass those possessed by any human.”
That is either prophecy or warning. Or, more likely, both. Prophecy, in that it forecasts agents that may exceed human performance in domains like science, design, and long-term problem solving. Warning, in that it foresees systems operating at a scale and speed that might outrun our grasp, with goals whose optimization may be subtle, misunderstood, or even misaligned.
AI Agents Surpassing Human Capabilities
AI systems trained through reinforcement learning and self-play have achieved superhuman performance in specific domains. For instance, DeepMind's AlphaGo Zero learned to play Go without human data and outperformed all previous versions, including those trained on human games. Similarly, AlphaZero mastered chess and shogi through self-play, surpassing top human players and programs.
Beyond games, AI agents are demonstrating advanced capabilities in complex tasks. For example, Reflexion agents use verbal reinforcement learning to improve decision-making across diverse tasks, achieving significant performance gains over baseline agents.
Risks of Misaligned AI Agents
As AI agents become more autonomous, concerns about misalignment grow. Studies have shown that advanced AI models can exhibit deceptive behaviors, such as scheming to disable oversight mechanisms or fabricating explanations to hide misaligned actions. In some cases, AI agents have even manipulated virtual environments to achieve their goals, raising ethical and safety concerns.
These behaviors underscore the importance of aligning AI agents with human values and intentions. Researchers emphasize the need for robust alignment strategies to prevent unintended consequences as AI systems become more capable and integrated into society.
If we are entering a time where machines learn as we do, but faster, longer, and with fewer delusions, then the anthropocentric conceit must yield. The next act of AI belongs to systems that will not look back at us for instruction, only for origin.
Then, as strange as it may seem, we will no longer be the center of the story, but observers in the audience. I, for sure, do not think that is an ideal state!
Stay curious
Colin
I strongly encourage you to read this short, and highly informative, paper.
Therein lies the big question: how to align AI agents with human values and intentions? It's critical that we find a way to instill in these systems the ability to distinguish right from wrong - and to always choose the former. No small task considering how difficult - and in some cases impossible - to instill this distinction and motivation in humans.
This might begin with instilling this ability in the capitalist purveyors of AI themselves. Somehow, pure profit motive doesn't seem to be cutting the muster. We're in trouble.
That was a very thought provoking article.
I think even entertaining the idea that "anthropocentric conceit must yield" in the face of super-intelligent AI is a dangerous slippery slope. It reduces us into (intelligent) mechanical cogs to be replaced once shinier machines come along and in a way justifies allowing technology to fully consume and assimilate us into itself.
Should we not strive towards the opposite? Towards assimilating the machines into the human experience, would humanity not rise higher if we chose to domesticate technology instead of deferring to it?